Why VLMs still can't reason about 3D space — and what we can do at inference time
TL;DR. State-of-the-art VLMs still fall apart on basic 3D spatial questions — and just adding more training data isn’t fixing it. Bolting a 3D encoder onto the input layer doesn’t help much either. The interesting frontier is inference-time: how do we get the model to actually think in space, not just describe it?
The problem is more annoying than it sounds
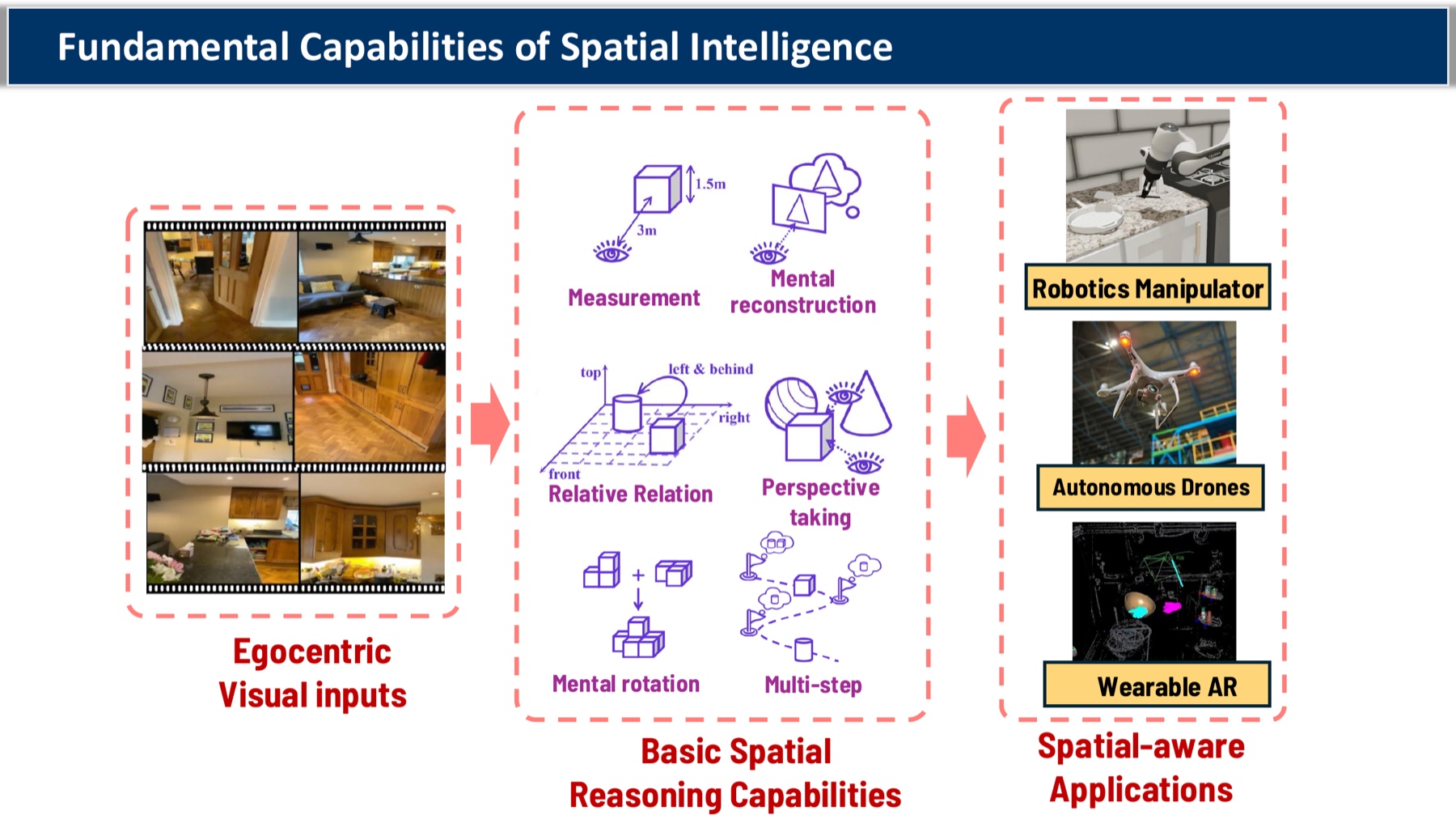
Spatial reasoning is the unflashy backbone of every embodied application I care about — pick-and-place manipulators, autonomous drones, wearable AR, anything that has to know “is the cup to the left of the laptop, and how far?”.
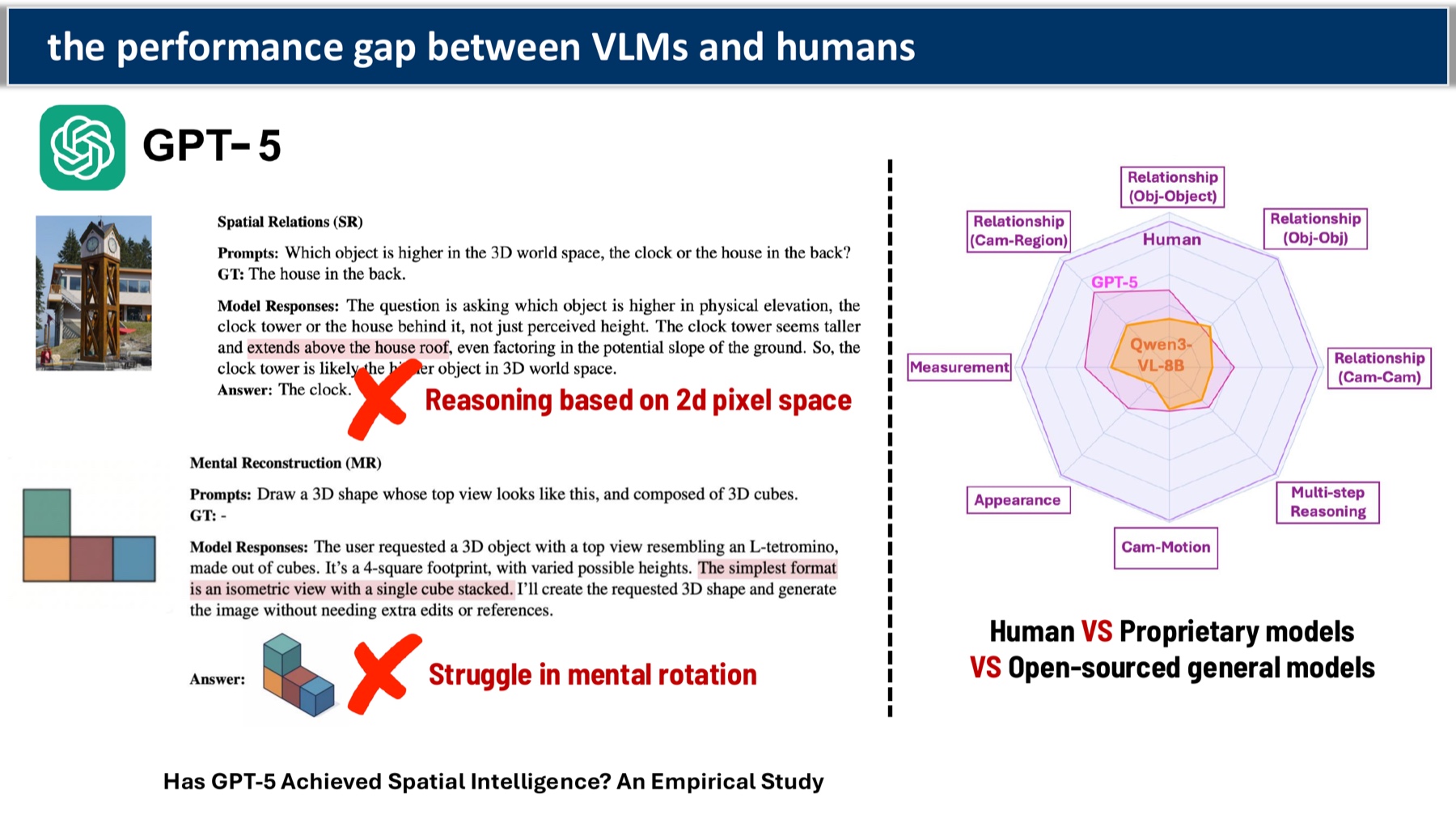
The benchmarks tell a humbling story. On basic visual cognition tasks, GPT-5 and InternVL3 sit at human-comparable levels (78–79%). On spatial reasoning tasks — the same models drop to 25–36%, while humans are still at 95%. The gap isn’t closing the way it has for language or general perception.
Throwing more data at it has hit a wall
The first instinct is the obvious one: keep scaling. Train on more spatial data. But the curves are flattening — measurement-style tasks plateau after about 2M samples, and multi-step spatial reasoning barely moves.
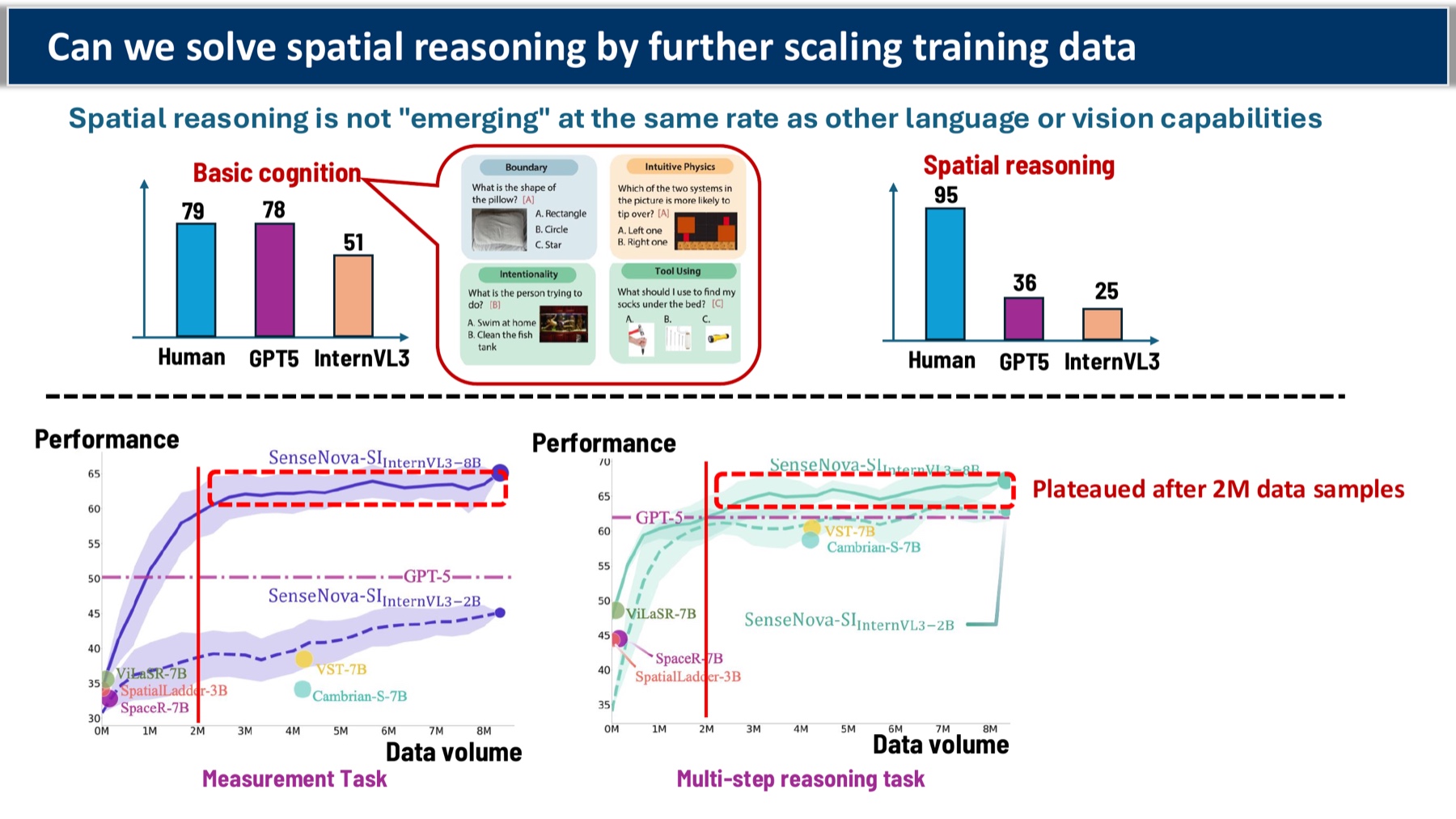
Why? Because the bottleneck isn’t exposure. It’s that the model has no mechanism for actually maintaining a mental 3D scene. You can show it a million top-down floor plans; at inference time it’s still doing 2D pattern matching.
“Just add a 3D encoder” — also a trap
The next instinct: bolt a 3D point-cloud (or depth) encoder onto the input layer, fine-tune, done.
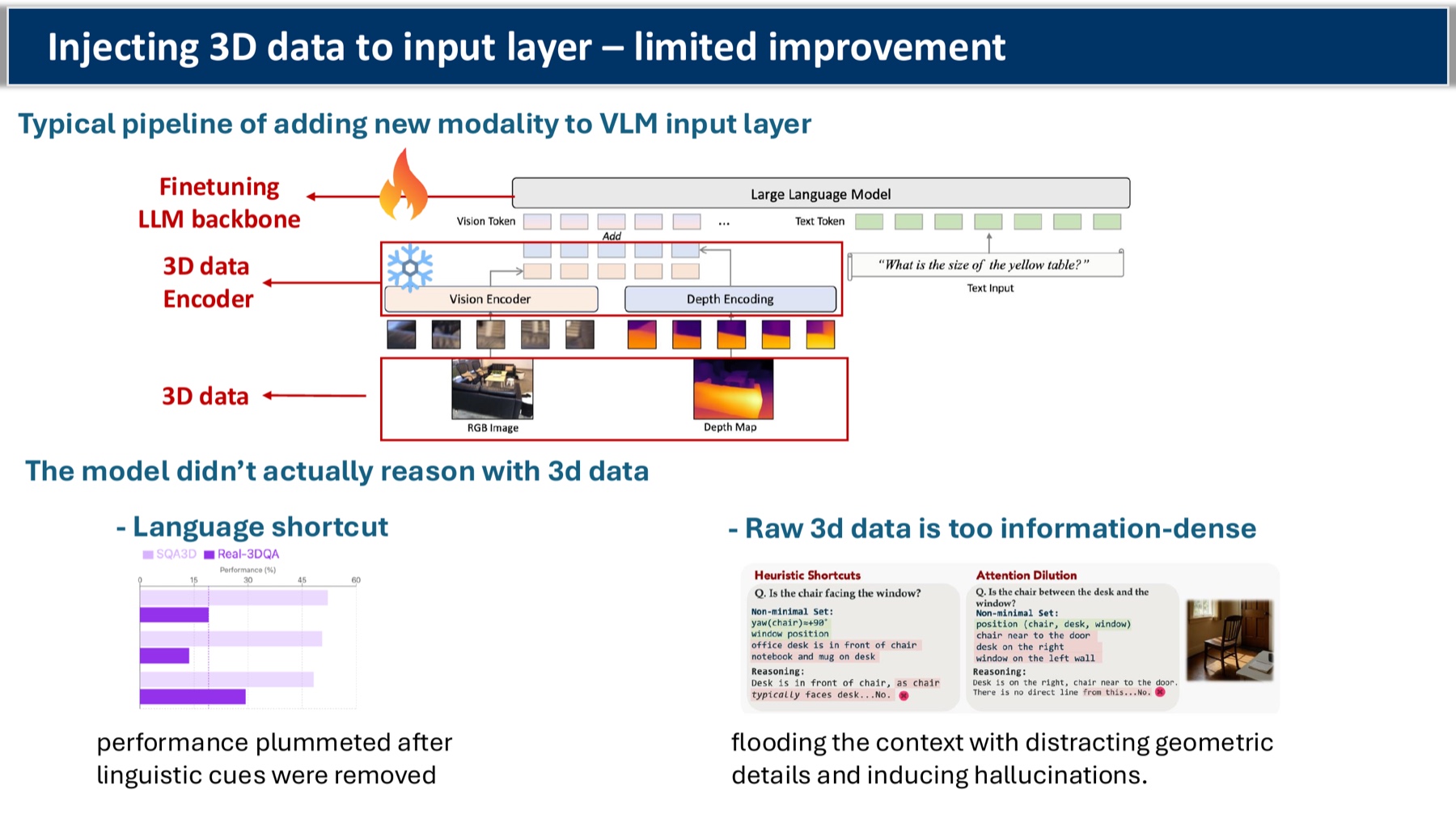
We tried this. The improvement is small and the failure mode is funny:
- Pull out the language hints (anything that mentions object names by position) and accuracy collapses. The model was reading the text, not the geometry.
- Stuff in the raw 3D data and you flood the context with low-level point coordinates that drown out anything semantically useful. Hallucination rate goes up.

So the model was either cheating with language shortcuts or being overwhelmed by raw geometry. Neither of those is reasoning.
Inference-time scaling is where it gets interesting
There’s a well-known trick from the text-reasoning world: at inference time, give the model more thinking budget — longer chain-of-thought, self-consistency, search. Performance scales with compute. The “aha moment” is real.
The annoying thing is that thinking in text actively hurts spatial reasoning. Verbalizing a 3D scene into tokens compresses away the geometry. So the question becomes: how do you scale inference-time compute without dumping everything into language?
Four directions on the table:
- Think with images. Crop, zoom, attend to task-relevant regions. Useful for focusing the model, but it doesn’t actually extract spatial structure — it just tells the VLM where to look.
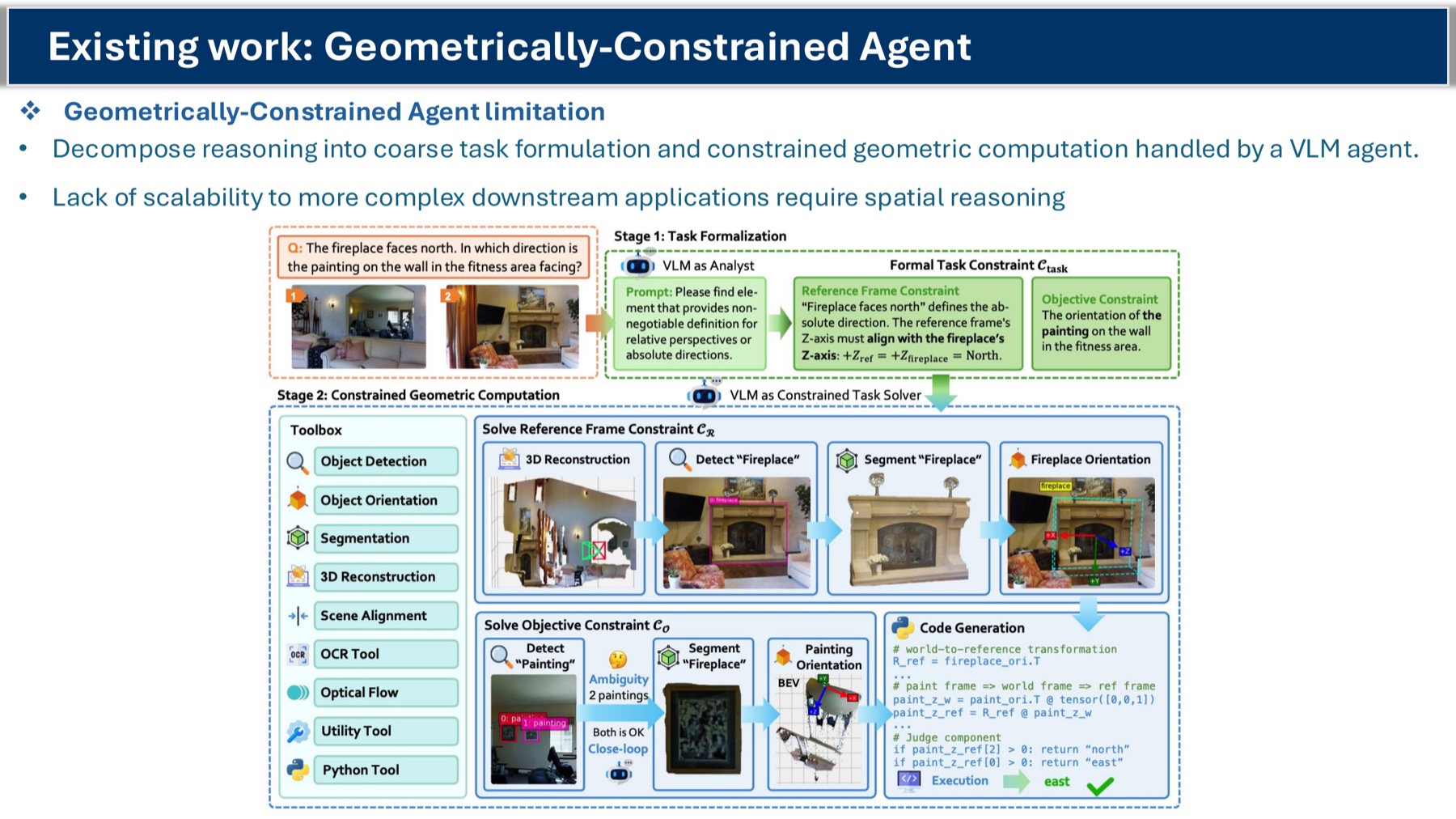
- Think with 3D-aware tools (agentic). Treat 3D understanding as an external module. The model calls “verify the layout” or “measure this distance” as tool calls. This is the most interpretable path; it separates semantic reasoning from geometric computation. Open question: can it scale to messy downstream tasks like navigation in a cluttered apartment?
- Think in a semantically-rich latent space. Skip the verbal bottleneck entirely — reason in continuous vision-language latents, with 3D structure injected as a latent token rather than as raw geometry or as text. Recent work uses VGGT-style 3D encoders + GRPO-based RL to nudge the latents in this direction. Current limitation: only dense 3D features get into the latent; fine-grained 2D supervision at intermediate steps is missing.
- (My favorite) Step-level spatial supervision. When the camera moves between views, the model loses track of what corresponds to what. So inject a
[2D latent token]per view, conditioned on the camera pose, and supervise reasoning at each view transition.
![Proposed pipeline: extract step-level spatial cues from per-view inputs using a 3D VGGT encoder, plus camera-pose tokens, fed into the VLM as [3D latent token] and [2D latent token] interleaved with text tokens.](/blog_images/vlm-spatial/slide-15.jpg)
The idea is to give the latent reasoning chain explicit anchor points the way chain-of-thought tokens anchor verbal reasoning.
Where I’m headed
Two threads I’m pulling on right now:
- An agentic workflow layered on top of a VLM-based mobile robot — using 3D tools and learned navigation skills to handle dynamic blocking and rerouting. The robot doesn’t need a perfect spatial map; it needs to know when to query a tool.
- A latent-supervision setup where step-level 2D spatial cues are extracted from the input views and used as targets during multi-step reasoning. Early experiments suggest entropy and probe-loss are decent signals for whether the model is actually maintaining spatial coherence (vs. confabulating).
Both feel like they’re attacking the right thing: not making the model see better, but making the model reason in a space where geometry has somewhere to live.
References & further reading
Our own work this draws on
- InfiniBench: Infinite Benchmarking for Visual Spatial Reasoning with Customizable Scene Complexity — Wang, Xue, Gao. CVPR 2026 (Oral). arXiv:2511.18200. The benchmark backing many of the numbers above.
- Uncovering and Shaping the Latent Representation of 3D Scene Topology in Vision-Language Models — Wang, Gao. [Paper] / Code. Direct evidence that VLMs carry a latent topological map, and the regularizer that makes it usable.
- MosaicThinker: On-Device Visual Spatial Reasoning for Embodied AI via Iterative Construction of Space Representation — Wang, Xue, Liu, Gao. arXiv:2602.07082. Inference-time fusion of cross-frame cues for small on-device VLMs.
- Reasoning Path and Latent State Analysis for Multi-view Visual Spatial Reasoning — Xue, Liu, Wang, Wang, Wu, Gao. arXiv:2512.02340. Cognitively-grounded analysis showing where in the reasoning chain VLMs actually break.
Background and related work
- VGGT — Visual Geometry Grounded Transformer, the 3D encoder cited as a feature source in the latent-reasoning pipeline.
- GRPO — DeepSeekMath / DeepSeek-R1 (Shao et al.), the RL recipe powering recent latent-reasoning work.
- Inference-time scaling in the text domain — OpenAI o1, DeepSeek-R1. The “aha moment” reference.
- “Think with images” line of work — VLMs that crop/zoom on tool-call-like primitives (e.g., V*).
The slides
The deck this post is built from: scaling visual spatial reasoning at inference time (PDF).
Always happy to chat about any of this — haw200 [at] pitt.edu.