Spatial latent reasoning — a reading map
This is my running map of the spatial-latent-reasoning subfield — what I’d hand a new student if they asked “where do I start reading?”. It’s organized by what the paper is trying to solve rather than venue or year, with my one-line takeaway after each cluster. Built from the talk slides; the full deck (with diagrams) lives here as a PDF.
1. Where VLMs actually stand on spatial reasoning
The starting point: real, sober numbers on how far VLMs are from human-level spatial intelligence.
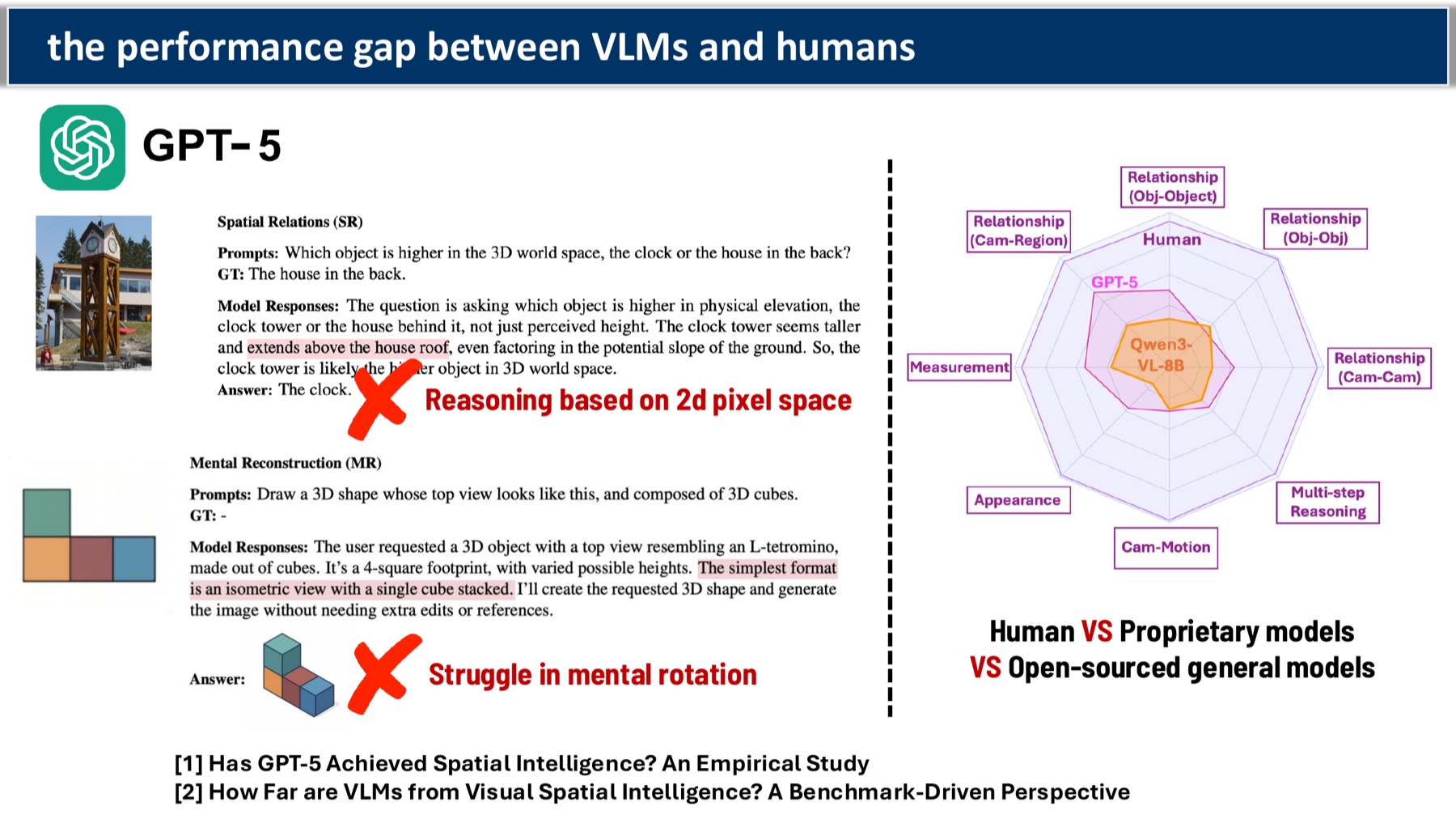
- [1] Has GPT-5 Achieved Spatial Intelligence? An Empirical Study — a sobering systematic eval; GPT-5 is still well behind humans on mental rotation.
- [2] How Far are VLMs from Visual Spatial Intelligence? A Benchmark-Driven Perspective — pairs benchmark numbers with failure-mode taxonomies.
My takeaway: The gap is bigger than the recent excitement suggests; basic 2D-pixel-space reasoning still dominates the failure modes.
2. Scaling data and model size — does it close the gap?
The “just train more” hypothesis, stress-tested.
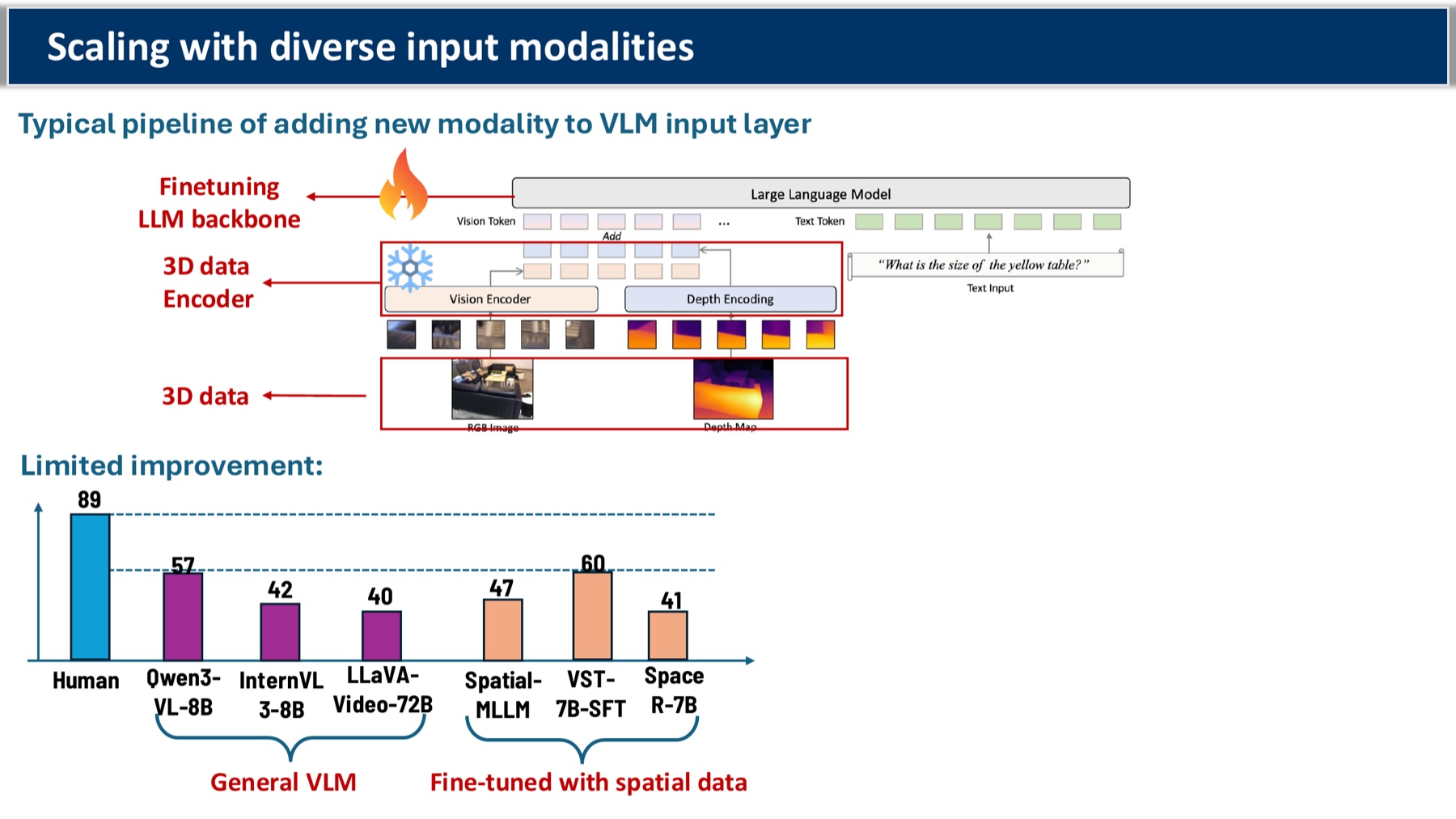
- [3] Why Do MLLMs Struggle with Spatial Understanding? A Systematic Analysis from Data to Architecture — decomposes the bottleneck across data quality, encoder choice, and projector design.
- [4] Scaling and Beyond: Advancing Spatial Reasoning in MLLMs Requires New Recipes — argues we need architectural changes, not just bigger pretraining sets.
My takeaway: The plateau is real. Pretraining-data thinking is a dead end for spatial; the leverage is in inference-time mechanism.
3. Adding 3D modalities at the input layer
The next-most-obvious fix: hand the model raw 3D as input.

- [5] Learning from Videos for 3D World: Enhancing MLLMs with 3D Vision Geometry Priors
- [6] S²-MLLM: Boosting Spatial Reasoning of MLLMs for 3D Visual Grounding with Structural Guidance
- [7] SD-VLM: Spatial Measuring and Understanding with Depth-Encoded Vision-Language Models
- [8] SpatialRGPT: Grounded Spatial Reasoning in Vision Language Models
My takeaway: Even the better-designed 3D-input papers leave a yawning gap to humans. The bottleneck has moved upstream: the model needs to reason with 3D, not just be shown it.
4. Inference-time scaling — thinking with images (world models)
If text-CoT compresses geometry away, can we make the “thinking” itself visual?
- [9] Mind Journey: Test-Time Scaling with World Models for Spatial Reasoning
- [10] When and How Much to Imagine: Adaptive Test-Time Scaling with World Models for Visual Spatial Reasoning
- [11] SpatialDreamer: Incentivizing Spatial Reasoning via Active Mental Imagery
- [12] WMNav: Integrating Vision-Language Models into World Models for Object Goal Navigation
- [13] Sparse Imagination for Efficient Visual World Model Planning
My takeaway: Useful primitive, but most of these just redirect the model’s attention. They don’t extract richer spatial structure than the input already gave.
5. Inference-time scaling — thinking with 3D tools (agentic)
Treat 3D understanding as something the model calls, not something it does.
- [14] World2Mind: Cognition Toolkit for Allocentric Spatial Reasoning in Foundation Models
- [15] Geometrically-Constrained Agent for Spatial Reasoning — the most-cited reference for the “tool-call decomposition” framing.
- [16] RieMind: Geometry-Grounded Spatial Agent for Scene Understanding
My takeaway: Most interpretable path. Open question: does it scale to messy downstream tasks (navigation, manipulation) where you don’t know which tool to call?
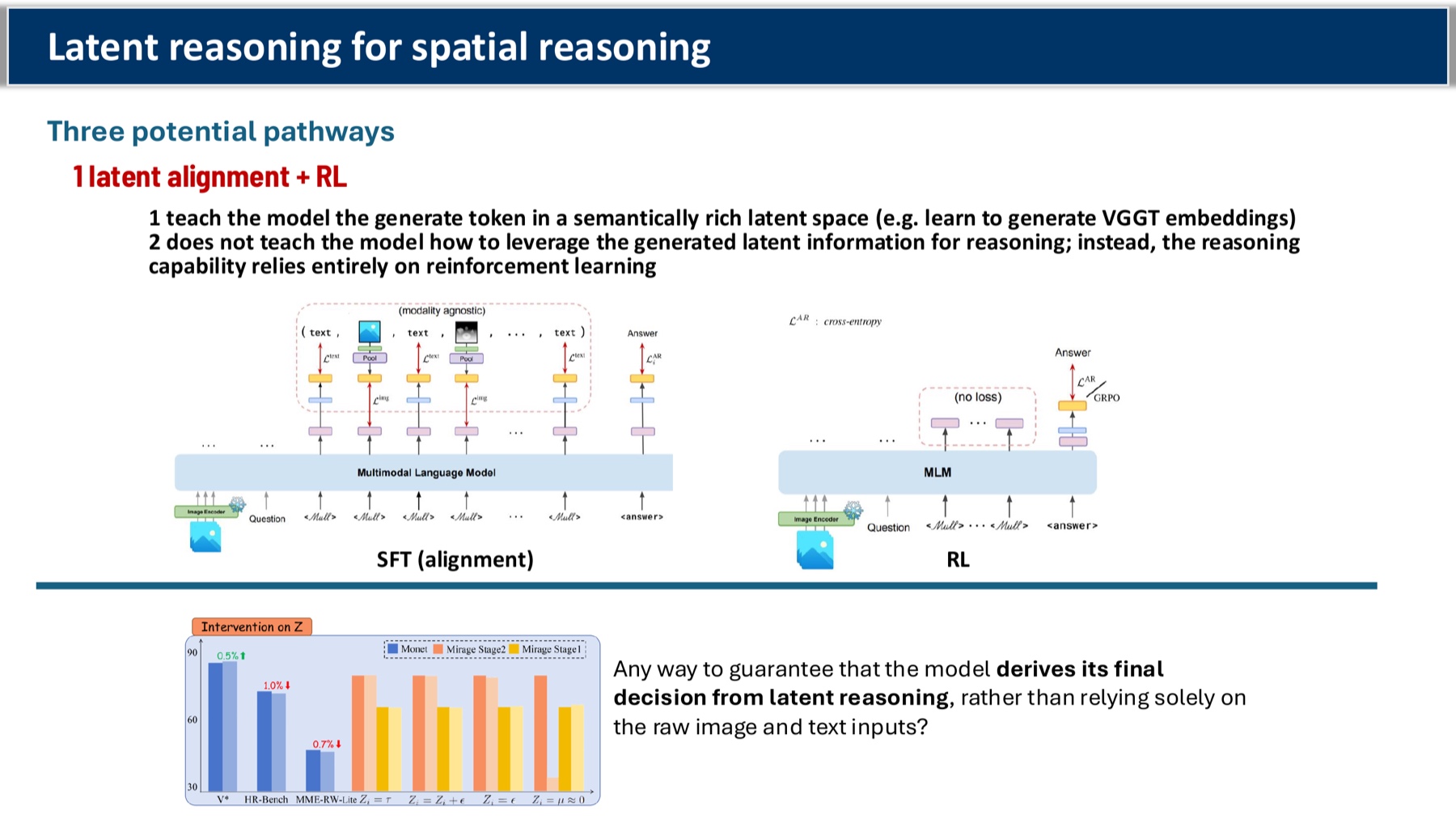
6. Latent reasoning — pathway A: latent alignment + RL
Skip language entirely; let the model think in continuous latents shaped by RL.

- [17] Think with 3D: Geometric Imagination Grounded Spatial Reasoning from Limited Views
- [18] Monet: Reasoning in Latent Visual Space Beyond Image and Language
- [19] CrystaL: Spontaneous Emergence of Visual Latents in MLLMs
- [20] Mull-Tokens: Modality-Agnostic Latent Thinking
- [21] Reasoning Within the Mind: Dynamic Multimodal Interleaving in Latent Space
- [22] Latent Chain-of-Thought for Visual Reasoning
- [23] Latent Reasoning VLA: Latent Thinking and Prediction for Vision-Language-Action Models
My takeaway: Elegant, but the open question is sharp: there’s no guarantee the model derives its decision from the latent reasoning chain rather than from the raw inputs. Probing this is wide open.
7. Latent reasoning — pathway B: ground-truth reasoning traces
Use supervision at the latent reasoning step (highlight task-relevant regions, sketches, mental imagery).
- [24] Sketch-in-Latents: Eliciting Unified Reasoning in MLLMs
- [25] Vision-aligned Latent Reasoning for Multi-modal Large Language Model
- [26] Interleaved Latent Visual Reasoning with Selective Perceptual Modeling
- [27] VisMem: Latent Vision Memory Unlocks Potential of Vision-Language Models
- [28] Multimodal Reasoning via Latent Refocusing
My takeaway: This is the cleanest path if you can collect step-level traces. The bottleneck is data curation, not modeling.
8. Latent reasoning — pathway C: world-model-guided
Use a world model to roll out future states; supervise the latent against the rollout.
- [29] Latent Chain-of-Thought World Modeling for End-to-End Autonomous Driving
- [30] LaST-VLA: Thinking in Latent Spatio-Temporal Space for Vision-Language-Action in Autonomous Driving
- [31] Can World Models Benefit VLMs for World Dynamics?
- [32] JEPA-VLA: Video Predictive Embedding is Needed for VLA Models
- [33] Policy-Guided World Model Planning for Language-Conditioned Visual Navigation
My takeaway: Beautiful when the task is action-conditioned (“what’s there if I turn right?”). Awkward for relational queries (“what’s the spatial relation between A and B?”) where there’s no obvious action to condition on.
What I’d read first
If you only have an afternoon: [2] for the empirical lay-of-the-land, [15] for the cleanest agentic framing, and [18] + [24] as the two contrasting latent-reasoning recipes (RL-driven vs. trace-supervised). That’s enough to triangulate where the field is and where the holes are.
If you want the full talk this is based on, the deck is here (PDF). I’ll keep this page updated as new work lands — flag me if I’ve missed something obvious: haw200 [at] pitt.edu.